
Hi Hans,
On 4 Oct 2018, at 4:01 am, Hans Hagen
It is important to get this fixed, else many otherwise perfectly fine documents will fail Preflight validation checks, for modern PDF standards.
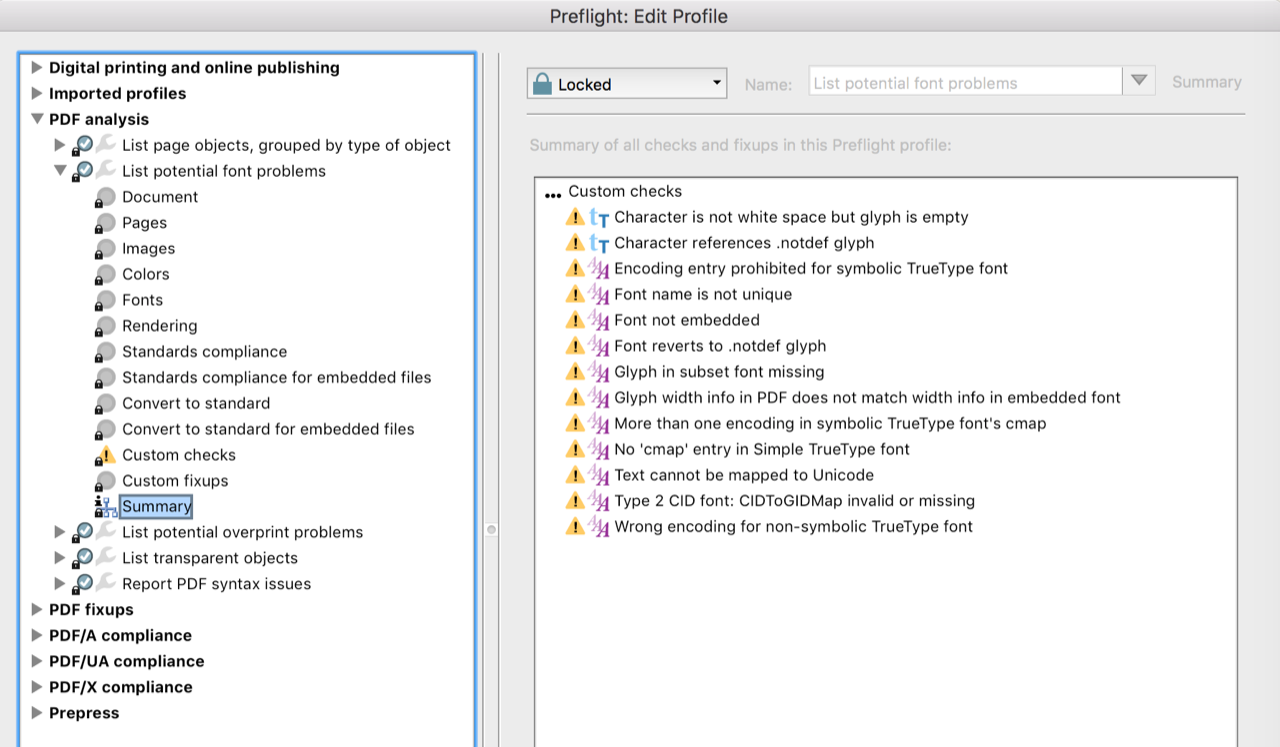
one can argue that the validator is wrong ... the subsetted basefont that is used is the same but it's accessed with different encodings which refer to the same subsetted font It’s not a validator so much as specialised checking for things that might be issues with some software. See the image for the tests being run. [cid:AA1B1B53-B4F5-4A26-B915-BA3485FC59D7@telstra.com.au] I’m mostly interested in the “mapped to Unicode” check, and have found hundreds of instances from various TeX fonts where this has not been so. In particular, I have a new file glyphtounicode-ntx.tex which contains mappings for glyphs used in the newtx fonts into unicode equivalents, often as sequences rather than a single code point. Indeed your example below has helped identify 6 more entries for this file. Most of those checks are not done with PDF/A or PDF/UA. However, that doesn’t preclude them from future standards. Having consulted the ISO 32000 (PDF 1.7) standard, the relevant sections are • §9.6.4 (Font Subsets) where it says: … different subsets in the same PDF file shall have different tags. and • §9.6.2 Table 111 – Entries in a Type 1 font dictionary BaseFont "For Type 1 fonts, this is always the value of the FontName entry in the font program;” This condition on BaseFont fixes the name to match what is used in the actual subset font. It seems that TeX is building further subsets of an already subsetted font. The names for these are then set by the requirement to match the common BaseFont name. But that then violates the requirement for different tags with different subsets; this is what the test is reporting. So it seems that this further subsetting of an already subset font is a rather suspect action… … though I can’t see much alternative, when you want Type 1 subsets of a font requiring more than 256 characters to be supported, in all. Maybe we shouldn’t be doing that? What would this mean for other parts of TeX? Since neither PDF/A nor PDF/UA actually check for this, there is no real problem yet. There are no explicit tests for PDF 1.7 compliance. It’s not clear whether this will become an issue with future standards; e.g., with PDF 2.0. Time will tell. Yet it’s probably worth thinking about, in advance. a larger test: Actually I encountered the issue with complete font-tables for the fonts in newtx (both newtxmath and newtxtext ). Karl requested a smaller example so that is what I provided. \font\fonti =fxlri-7alt \font\fontii=fxlri-7letters {\fonti \char"04}\par {\fontii A B C}\par \count99=0 \def\foo{ \char\count99 \advance\count99 1 \ifnum\count99<256 \expandafter\foo \fi} {\font\fonta=texnansi-qplr \fonta \foo}\par {\font\fonta=ec-qplr \fonta \foo}\par {\font\fonta=qx-qplr \fonta \foo}\par {\font\fonta=t5-qplr \fonta \foo}\par {\font\fonta=qx-qplr-sc \fonta \foo}\par \bye This tests a lot of glyphs, thanks. It helped me find some new glyph names without a known map to Unicode. this will still use one font resource with > 256 characters (and a bit bogus encoding in the pfb blob which actually can be StandardEncoding) Surely this is true only for a subset of the font. Assistive Technology needs to extract proper characters (unless over-ridden by alternative text), so it would not be appropriate to declare StandardEncoding. so it's a rather old situation i think ... and changing that will demand big changes (so not something done quick as one never knows what side effects occur) e.g. one font resource per subset (so larger files too) Yes; I think that is what may need to be done, if a format or standard requires it. Just not yet. (the same in luatex but there one will normally use wide fonts which don't have that problem and there are subtlke differences between the engines) The TeXGyre fonts seem to have 500+ glyphs. It may be that we are creating the problem for ourselves by using Type 1 encodings that are subsets limited to at most 256. This approach seems to work now, but is it reliable into the future? (acrobat X - i have no newer version - preflights ok) Many more tests have been added in the past few years. The interface changed significantly too, about the time when tests for PDF/UA were added. I find it to be an extremely powerful tool, which is very easy to use. Given there’s no Open Source equivalent, I must say that it alone is well worth the licensing fee for Acrobat Pro. Hans Cheers. Ross Dr Ross Moore Mathematics Dept | 12 Wally’s Walk, 734 Macquarie University, NSW 2109, Australia T: +61 2 9850 8955 | F: +61 2 9850 8114tel:%2B61%202%209850%209695 M:+61 407 288 255tel:%2B61%20409%20125%20670 | E: ross.moore@mq.edu.aumailto:rick.minter@mq.edu.au http://www.maths.mq.edu.auhttp://mq.edu.au/ [cid:image001.png@01D030BE.D37A46F0]http://mq.edu.au/ CRICOS Provider Number 00002J. Think before you print. Please consider the environment before printing this email.http://mq.edu.au/ This message is intended for the addressee named and may contain confidential information. If you are not the intended recipient, please delete it and notify the sender. Views expressed in this message are those of the individual sender, and are not necessarily the views of Macquarie University.http://mq.edu.au/
{kind=link}
{kind=link}